redis知识总结
redis
一、redis三兄弟
- 穿透
- 击穿
- 雪崩
穿透
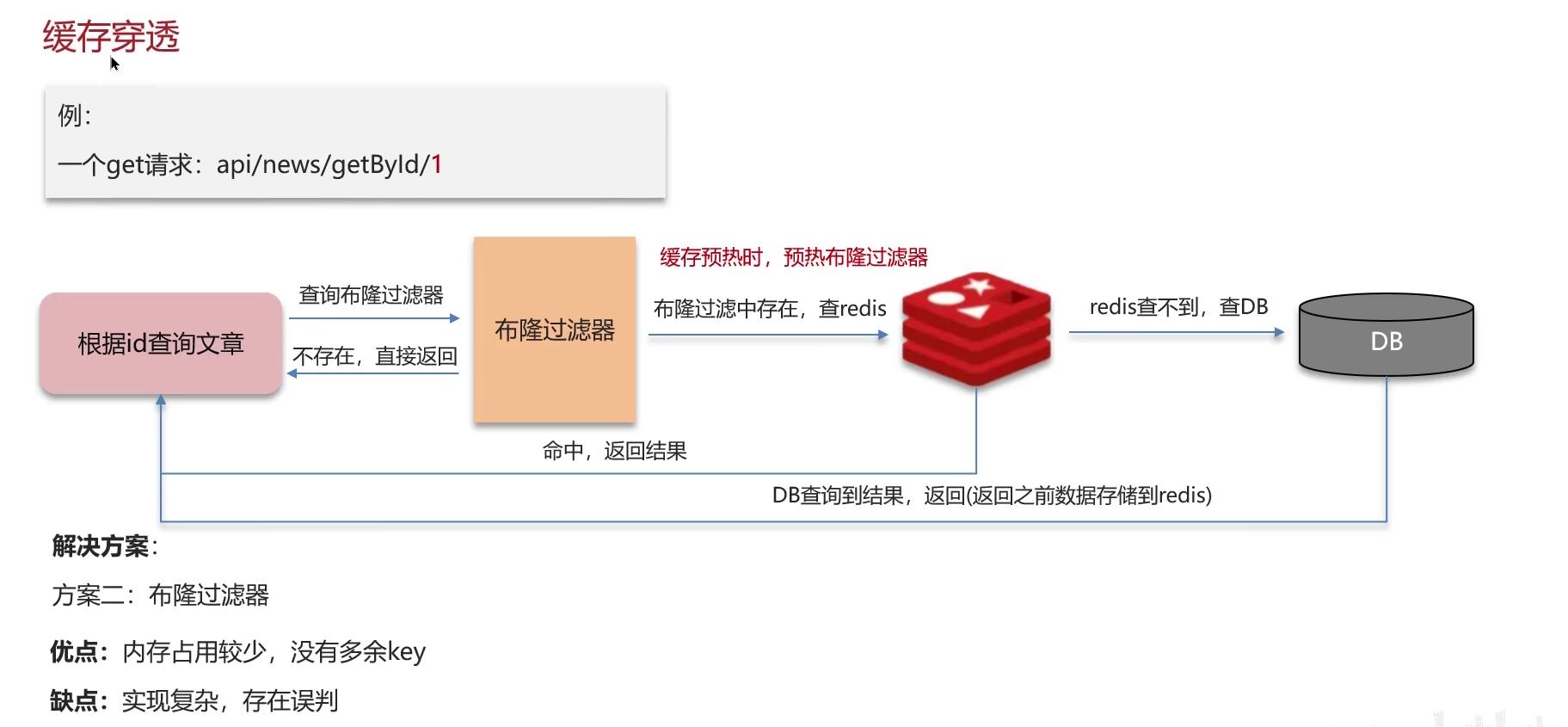
穿透是指,查询一个不存在的数据,mysql查询不到,也不会写入缓存,导致每一次请求都会查询数据库,大量的请求导致宕机。
原因是:①:可能是路径被人恶意攻击,redis没有相对应的数据,所以去查询数据库,但大量的查询操作执行的时候,数据库就会被压垮。
解决:
- 布隆过滤器
- null返回
击穿
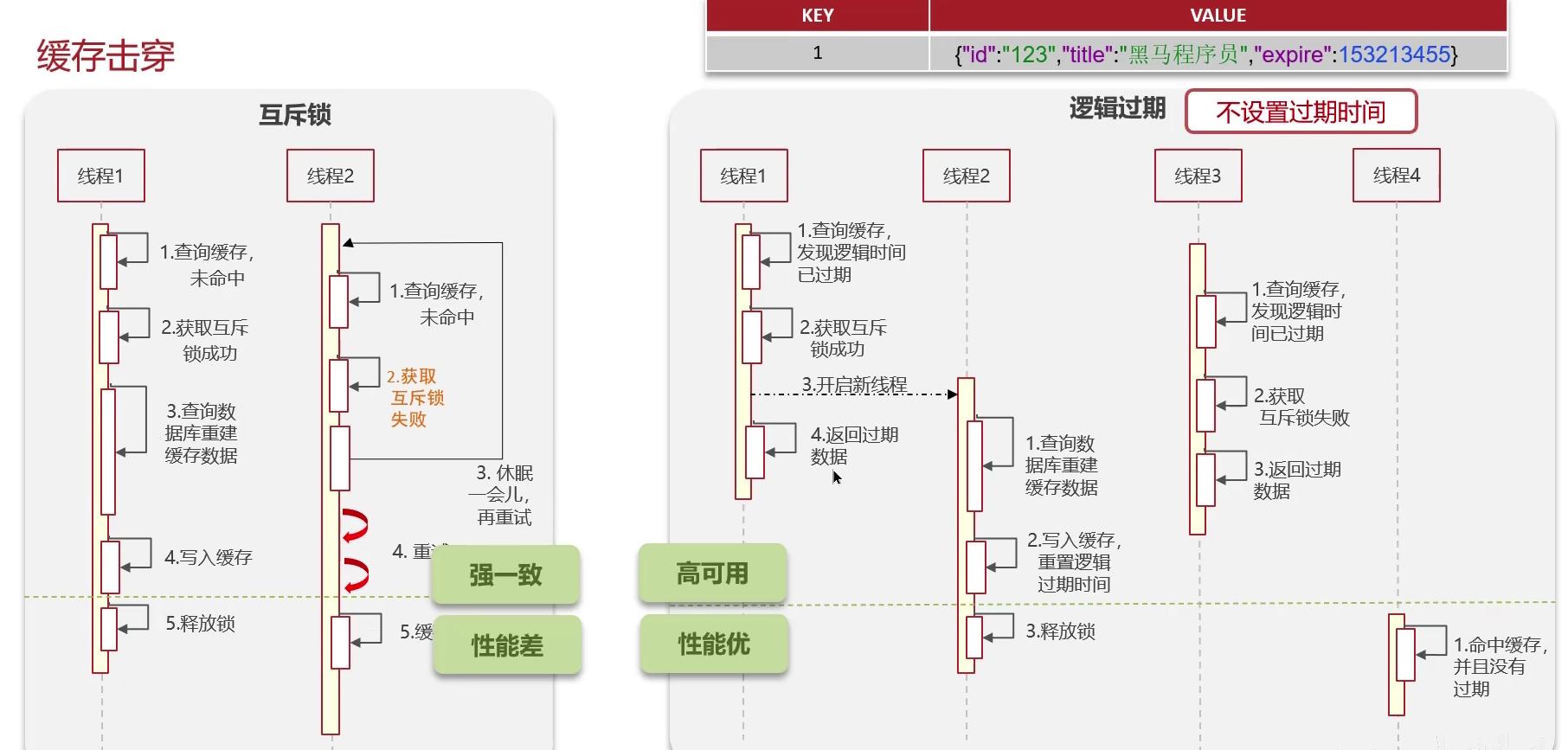
击穿是指,当某一个key过期的时候,大量请求无法在redis中查询,转而去数据库查询,一时间大量的查询导致数据库压力过大。
原因是:①:key过期了
解决:
- 加锁,分布式锁。互斥锁(保证强一致性、性能差一点)
- 逻辑过期(高可用、性能优)
雪崩
雪崩是指在同一时间段大量的缓存key同时失效,或者redis宕机,导致大量的请求到数据库,带来巨大的压力。
原因:key失效,redis宕机
解决:
- 给不同的key设置TTL随机过期值
- 利用redis集群提高服务的可用性 哨兵模式,集群模式
- 给缓存业务添加降级限流策略 ngxin或spring cloud gateway
- 多级缓存 guava或者caffeine
二、双写一致性(redis和数据库)
这种问题要结合业务进行回答,切记切记
双写一致性
当修改了数据库的数据时,需要同时去更新缓存的数据,缓存要和数据库的数据保持一致
读操作:读取命中直接返回,不命中查询数据库,写入缓存,再返回。
写操作:延迟双删
我们要延迟双删(删除缓存→删除数据库→删除缓存),原因是数据库双写不一致的问题。
需要强一致的话
分布式锁:
在读的时候添加共享锁,再写的时候添加排它锁。
共享锁:其他线程也可以读
排它锁:其他线程无法进行读写操作
特点:强一致性,性能低
不需要强一致性的话(最终一致性)
异步通知:MQ和canal
cannal:对代码无侵入,伪装mysql的一个从节点
- 主要是监听binlog文件,当数据库改变的时候,就会通知缓存变更情况。进行数据更新。
MQ:主要依靠 MQ的可靠性
- 修改数据的时候,就会有消息通知MQ,然后MQ监听缓存进行数据更新。
三、持久化
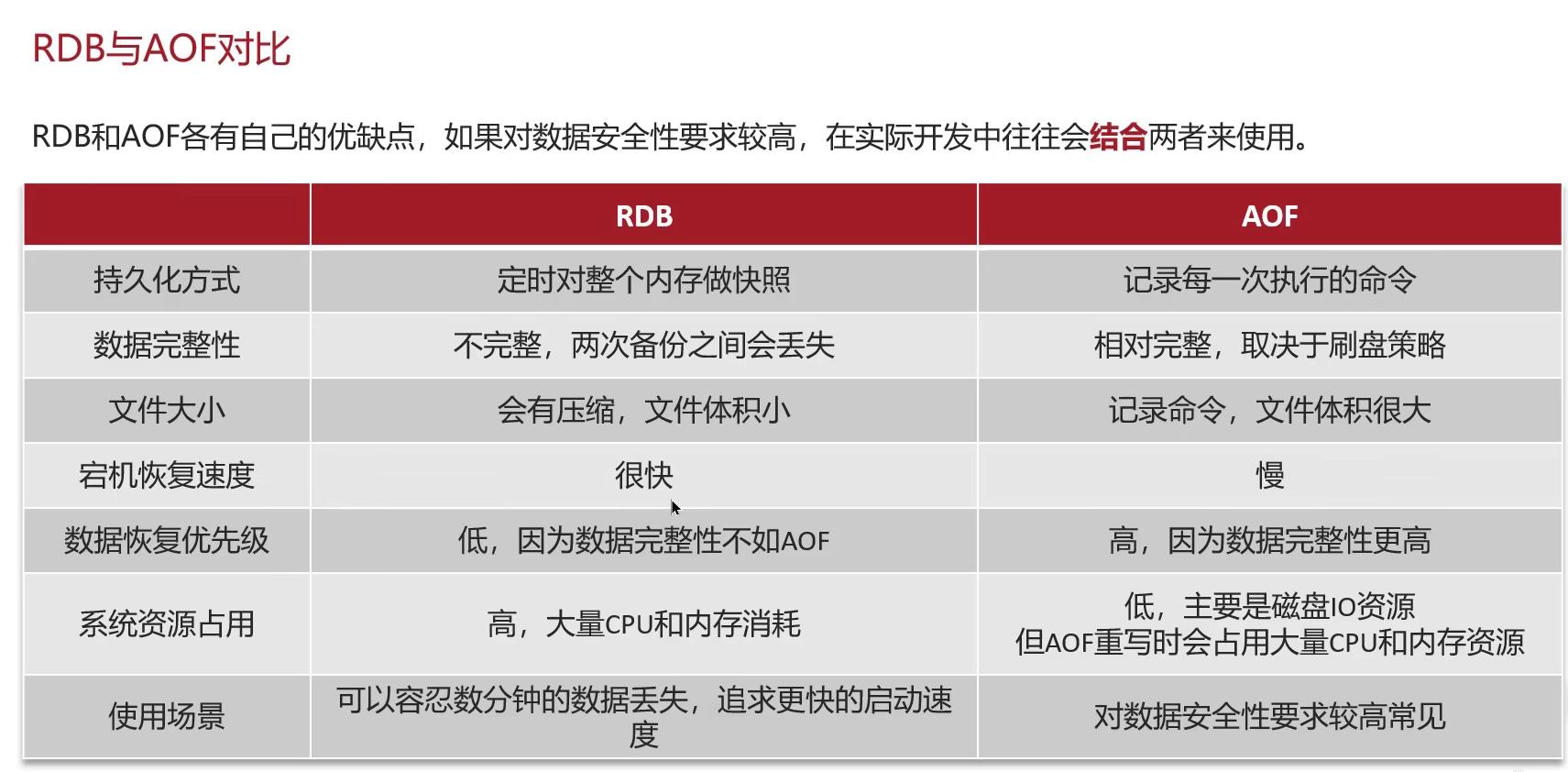
RDB
RDB:也就是redis的快照,简单来说就是把内存中的所有数据写入到磁盘中。当redis故障重启的时候,从磁盘读取快照,恢复数据
保存命令:
-
save:主进程执行,
-
bgsave:子程序进行运行,避免主程序收到影响(fork),子进程共享主进程的内存数据。原因是页表相同映射。
页表:记录虚拟地址与物理地址的映射关系。
AOF
AOF全称为append only File(追加文件)。redis处理的每一个写命令都会记录在AOF文件,可以看作是命令日志文件。
默认是关闭的,redis.conf来开启,也可以通过文件来修改频率。
- always:同步刷盘(可靠性高,几乎不丢失数据,但性能影响大)
- everysec:每秒刷盘(适中,最多丢失一秒的数据)
- no:操作系统控制(性能最高,可靠性差,可能丢失大量数据。
AOF的文件比RDB大,会记录一个key的多次操作但只有最后一次操作有效,通过执行bgrewriteaof来进行文件重写,用最少的命令达到一样的效果。
redis在触发阈值时会自动去重写AOF文件。阈值同样可以进行设置。
两者的区别
主要优缺点,RDB文件小,二进制,速度快,但是有丢失的风险。AOF文件大、速度慢,但是风险小。
四、数据过期策略
但key过期的时候,redis会立刻删除吗?
并不会!删除策略有两种,惰性删除和定时删除。
1. 惰性删除
当我们设置了过期时间之后,我们就不去管它了,只有用到这个key的时候才会去判断是否过期,如果过期就删除。
- 优点:对cpu很友好,只有使用的时候才会去调用过期检查,节省资源
- 缺点:对内存很不友好,若是不调用,它就一直呆在内存之中,浪费内存。
2. 定时删除
每隔一段时间,就对一些key进行检查,删除里面的过期key(从一定量的数据库中,取出一定数量的随机key进行检查,并删除过期的key)
2.1 SLOW
慢模式,定时删除,每次删除的间隔为10hz,也就是一秒十次(100ms/次),每次不超过25ms,可以通过配置文件中的HZ选项进行设置,来调整
2.2 FAST
快模式,执行的频率不固定,但执行间隔不低于2ms,每次耗时1ms。
2.3 优缺点
有点:通过限制频率来减少对于cpu的影响,同时也可以释放内存
缺点:难以确定删除操作的频率和时长。
五、数据淘汰策略
假如缓存过多,内存满了怎么办?
数据淘汰策略:8种
-
noeviction:默认,表示当内存满的时候不再添加新的key
-
volatile-ttl:对设置了ttl的key进行判断,越小,就越先被淘汰
-
allkeys-random:对所有的key进行随机淘汰
-
volatile-random:对设置了ttl的key进行随机判断
-
allkeys-lru:对所有的key执行lru策略,最后一次访问越久越先淘汰
-
volatile-lru:对设置了ttl的key执行lru策略。
-
allkeys-lfu:对所有的key执行lfu策略,访问次数越少的,越先淘汰
-
volatile-lfu:对设置了ttl的key执行lfu策略,访问次数越少的,越先淘汰
重点在于,要记住lru策略和lfu策略。lru(recently最少最近)lfu(frequently熟悉的最少评率)
对于使用什么策略的建议。
- 优先使用allkeys-lru来进行淘汰,如果业务有明显的冷热数据区分,推荐这个方法
- 如果业务中的数据没有冷热区分,访问的频率也差不多,推荐用allkeys-random
- 如果业务中有置顶的需求,那就可以用volatile-lru,对置顶数据不进行ttl的设置,只会淘汰其他数据。
- 如果时短时高频的需求,用lfu的两个策略。
问题:
1.数据库有1000万的数据,redis只能存20万,如何保证redis中都是热点数据呢?
答:用allkeys-lru来进行淘汰,删除最长时间访问的数据,保留热数据。
2.redis的内存用完了会发生什么?
答:数据淘汰,看你是什么设置,如果是默认norviction会直接报错。
六、分布式锁
1. 导读
例子,抢卷服务,会员兑换码等
如果有最后一张卷,结果是两个进程查询到了卷,先后获得了优惠卷,最后会导致票数超限。
为了解决这个问题,我们可以加锁。
如果是一台服务器中,我们可以直接用synchronized(this){}来进行锁的限制,可以解决这个问题。
** 但是!!!**在实际开发中,我们的程序时部署在多个服务器中的,这个时候synchronized锁就只能在一台服务器中使用,无法防止上述超限的问题发生。
这个时候就要用到分布式锁。
原理:
分布式锁的原理很简单,那就是拿一个中间人作为锁的管理,由它来监控锁。这里用的是redis。当8080服务器获取锁成功后,就给分布式锁做个标记,告诉分布式锁8080中的线程1已经获取锁了。
此后,其他服务器8081想要获得锁,分布式锁就会拒绝这个请求,加锁失败,程序进入阻塞状态。
2. redission实现
2.1 redis实现的分布式锁
对于redis实现分布式锁来说,用的是setNX来进行设置
1 | |
EX来设置它的过期时间,那么就有新的问题,这个过期时间多少合适?
解决办法有两个:①预估服务的时间后判断 ②看门狗自动续期
显然是第二个啊,看门狗机制来延长服务的时间,防止服务过期。一般这个续期的时间是服务设置时间的1/3。看门狗需要手动去通知停止。
1 | |
💡**注意:**如果手动设置了过期时间,那么看门狗机制就会失效,redis认为你可以自己管理时间。默认30s关闭时间。
💡**注意:**在底层中是用SETNX和lua脚本实现的。
2.2 redisson实现的分布式锁
💡:redisson中的分布式锁是可以重入的,而redis不可以。
重入锁是一种累计的重入次数值。
其中key是自己定义的唯一标识,而value是重入的个数。
分布式锁如何解决一致性的问题呢?
在服务写入数据的时候,redis宕机了,导致数据无法正常操作,这是后按照redis的机制,挑选从节点成为主节点。此时,就会出现两个线程有同一个锁。
为了解决这个问题,redis提供了红锁。(N/2 +1 )在多个实例上面加锁,从而避免这个问题。(很少用,性能很差,而且很复杂,很繁琐。)如果非要保证数据的一致性,可以使用zookeeper来实现。
七、redis集群方案
分类
- 主从复制
- 哨兵模式
- Redis分片集群
主从复制
介绍一下主从复制?
单节点Redis的并发能力是有上限的,要进一步提高Redis的并发能力,可以搭建主从集群,实现读写分离。一般都是一主多从,主节点负责写数据,从节点负责读数据,主节点写入数据之后,需要把数据同步到从节点中。
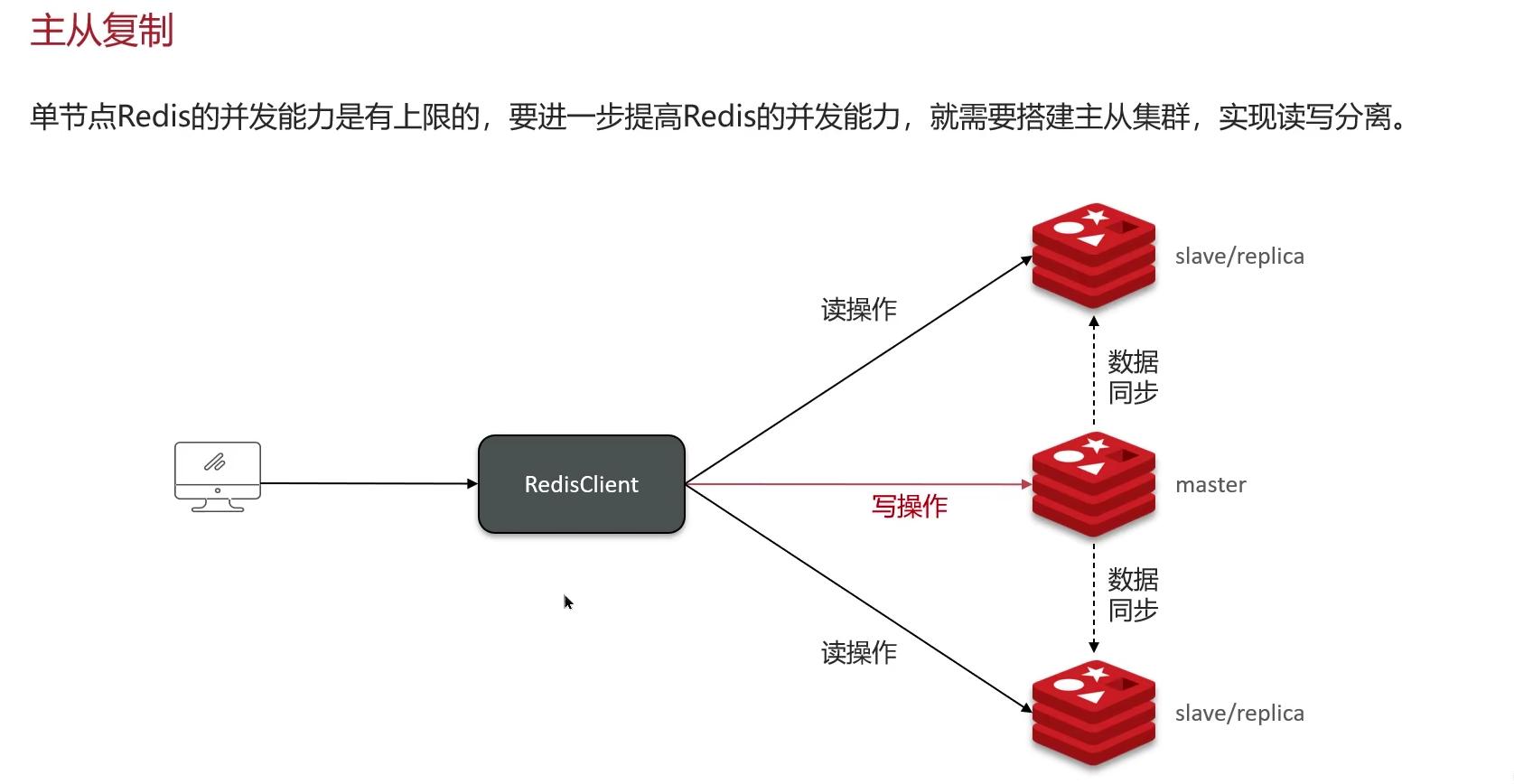
主从全量同步。直接看图吧。
- 全量同步:slaver发出请求,master判断是否为同一个集群id(是否第一次接收),如果是,就返回版本信息,并foke一个程序进行RDB生成和传递回去。slaver接收到版本后保存,随后清空数据用RDB加载数据。同时在执行上面过程中,如果数据有更行,master节点会发送执行期间的日志文件给slaver,slaver执行之后保持同步。
- 增量同步:如果是第二次的话,这个过程有点区别。slaver发出请求,master判断是否为同一个集群id,发现不是。master节点会发送执行期间的日志文件给slaver,slaver执行之后保持同步。
- 💡 笔记:需要注意的是,判断是不是第一次的一句是看集群id,判断日志文件的多少用的是偏移量。

哨兵模式
哨兵的构成:
-
哨兵也是集群的,至少三台
- 监控:哨兵sentinel会不断的检查master和slave是否按照预期工作
- 自动故障恢复:如果master故障,sentinel会将一个slave升级为master,当故障恢复后,也以新的master为主。
- 通知:sentinel充当redis客户端的服务来发现源,当集群发生故障转移时,会将最新消息推送给redis客户端(说人话就是不需要对代码进行修改,故障的时候会自动分配master)
-
服务状态监控
sentinel基于心跳机制监测服务状态,每隔1s向集群的每个实例发生ping命令:
- 主观下线:一台发现实例未在规定的时间响应
- 客观下线:超过指定数量(quorum)(一般是哨兵的一半以上(n/2+1))都认为主观下线,那么就认为是客观下线。
当判断下线之后,哨兵就会开始挑选新的master
- 判断主从节点断开时间的长短(越短越好),超过指定时间排除
- 判断优先级(slave-priority),越小越高
- 如果优先级一致,判断slave节点的offset值,越大优先级越高(也就是数据越多越好)
- 最后判断id运行的大小,越小优先级越高(这个无所谓)
-
脑裂问题
所谓的脑裂,就是当客户端断网之后(处于不同的网络分区),哨兵ping不通master,以为master挂了,所以把slave升级为master。(此时原来的master依旧可以写),等网络恢复之后,原来的master就被强制降级为slave。导致数据可能丢失。
解决办法:
- min-replicas-write 1 表示最少的salve节点为1个。
- min-replicas-max-lag 5 表示数据复制和同步的延迟不超过5秒。
- 这样设置之后,就导致旧的master写入请求的时候因为不符合上述的两个条件被拒绝,写入请求就会到新的master上,从而解决脑裂的问题
分片集群
主从和哨兵可以解决高可用、高并发读的问题。
但是依然有两个问题没有解决:
- 海量数据存储问题
- 高并发写的问题
使用分片集群可以解决上述问题,分片集群特征(作用):
- 集群中有多个master,每个masterf保存不同数据
- 每个master都可以有多个slave节点
- master之间通过ping监测彼此健康状态(代替哨兵)
- 客户端请求可以访问集群任意节点,最终都会被转发到正确节点
Redis分片集群中数据是怎么存储和读取的?
Redis分片集群引入了哈希槽的概念,Redis集群有16384个哈希槽,每个key通过CRC16校验后对16384取模来
决定放置哪个槽,集群的每个节点负责一部分hash槽。(有有效值看有效值,没有看key哈希值与16384取模)
redis为什么快
-
因为它是单线程,避免不必要的线程切换和竞争条件,同时不用考虑线程安全问题
-
存内存操作,执行快
-
IO多路复用,非阻塞IO(例如bgsave和bgrewriteaof都是后台执行)
-
内核空间和外核空间
- 内核空间:几乎具备所有权限的系统空间
- 外核空间:用户的操作空间
- 内核空间是中转站:外核空间-内核空间-硬件
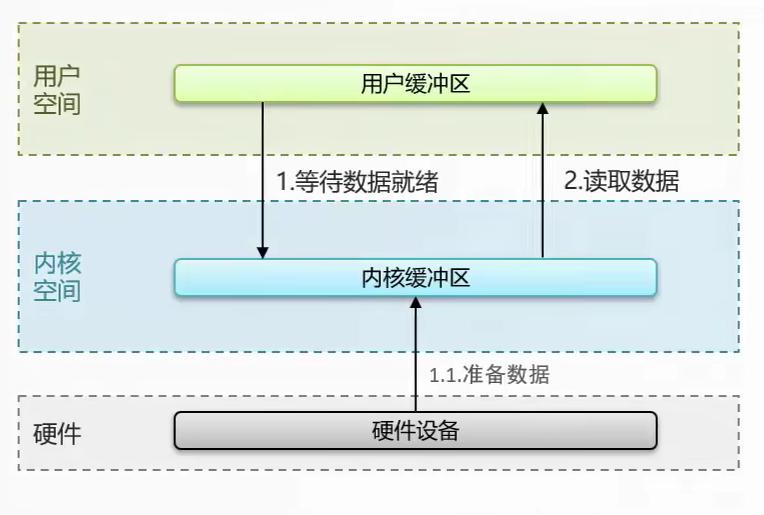
-
阻塞IO
在等待数据和准备数据的过程中是阻塞的,在拷贝数据的过程中也是阻塞的。
-
非阻塞IO
在等待数据和准备数据的过程中不是阻塞的,后面一样。但cpu消耗大
-
IO多路复用
单个线程可以一次性监听多个socket,虽然两个都是阻塞,但是一旦某个socket可读就会通知,避免无效等待。节省cpu,底层用epoll实现,在通知socket就绪的同时也通知是哪个socket。提升了性能
io多路复用的实现方式
-
select
-
poll
-
epoll
前两个都是通知系统但没有携带socket,需要一个个去找,epoll则会在通知系统就绪的时候提供socket的信息
-
-
-
Redis网络模型
就是使用l/O多路复用结合事件的处理器来应对多个Socketi请求
连接应答处理器
命令回复处理器,在Redis6.0之后,为了提升更好的性能,使用了多线程来处理回复事件
命令请求处理器,在Rdis6.0之后,将命令的转换使用了多线程,增加命令转换速度,在命令执行的时候,依然是单线程